Updated 12/23/2019 and 12/27/2019 – see end of article.
Revisited 11/1/2020 – see Revisiting Fry’s Electronics a year later
It’s worse than that, they’re dead, Jim – Fry’s Electronics is dead
As most of my readers know, Fry’s Electronics has been a mainstay in Silicon Valley culture since the mid-1980s. It’s spread around the country, from southern California to Texas and Arizona and the Midwest and probably locations I don’t even know about. There’s even one in Las Vegas.
The stores have themes, running from the Wild West theme of the Palo Alto location (the oldest continuously operating Fry’s store), to Las Vegas’s obvious Las Vegas Strip theme. The current (and third) Sunnyvale location is themed History of Silicon Valley, with an oscillator on the front, huge sepia photos of the founding people and events of Silicon Valley, and more.
But perhaps, like Halted and Weird Stuff in the past two years, this piece of Silicon Valley history may be coming to an end.
The first store opened in Sunnyvale in 1985, near the current location of Faultline Brewing (just off 101 and Lawrence Expressway). When I came to California just over 10 years later, it had moved to the “chip” themed building on Kern and Lawrence (white walls with black marks like an integrated circuit; the building is now a Sports Basement). Sometime in the late 1990s or early 2000s they built a new, enormous store at Arques and Santa Trinita, just a block or so from the Kern location. It had parking for hundreds of cars, almost a hundred cash registers, a cafe in the middle of the store, auto electronics installation bays on the side, and all in all it was a formidable experience.
I’ve never seen more than half of the registers in operation, but it’s often been crowded, and I’ve occasionally run into old friends and former colleagues… even those who had long since moved out of the area would come back like pilgrims.
Lately the parking lot has seemed impressively sparse, and fewer shoppers on most visits (except around the holidays and major TV-inducing sporting events). The shelves were usually well stocked, and things were often where you expected them.
But things keep changing.

A Sad Sunnyvale Visit
I went to Fry’s in Sunnyvale last Friday to look for a water filter cartridge. Didn’t think to check stock online first, but once I walked in, I knew I wasn’t going to find it.
The parking lot was the typical empty for a Friday afternoon, maybe a bit more. There were more old guys in the cafe than shoppers in the rest of the store. Lots and lots of empty shelves, far fewer staff than usual, felt like the last days of Orchard Supply Hardware but with fewer people and 10 times the space.
As I walked around, seeing what was left, I got the feeling that they could probably carve the store up… block off half of it and build a new entrance, for an entire second store… and still have plenty of room.
I ended up not finding my water filter cartridge. I did pick up a USB hub and a model train magazine though.
And maybe the strangest thing… As far as I can remember, for the first time in my 22+ years of going to Fry’s (since my friend Ray took me there in 1996 or maybe early 1997), there was nobody at the exit to check my receipt.
What happened to Fry’s?
There’s been a lot of media coverage of this, mostly columnists not entirely unlike me, looking at how the world has changed in the last ten years or so. You usually didn’t go to Fry’s for knowledgeable sales staff (although they’d be happy to read the box to you). Warm inviting environments were not their forte, and the “Fry’s Lending Library” (where you’d buy something to use for a day, or test out something else, before returning it) was definitely not part of their marketing, but a lot of people used that function of their stores, despite the long and drawn-out return process.
You went to Fry’s because if you needed almost anything, from a cable to a capacitor to a chair to a computer to a Coke to a charcoal grill, you could find a variety to choose from. You could pick up a magazine and a candy bar and a soda and a pack of batteries in the long check-out line. And it was almost always good for those things.
The biggest thing that happened to Fry’s was Amazon. And I’d say they started adjusting to Amazon about five years too late.
They acquired Cyberian Outpost in 2002 to build out their e-commerce business, and that went sluggishly. They started doing price-matching to local stores and online stores, but either trained their staff wrong or didn’t train them at all, which meant that even if a 4-port KVM switch was available and in stock 10 miles away, they’d try to match it to an 8-port switch and deny the match (happened to me, and I ended up taking the 10 mile trek).
As time went by, they merged outpost.com into frys.com and made it a better experience, including in-store inventory checking and in-store pickup. They’ve started doing price-matching smoothly and accurately, even to Amazon and Best Buy and Newegg. They even introduced same-day home/office delivery recently.
But the parking lots are more empty than not, the stores are hollow echoes of their past glory, and experts as well as fellow customers are having trouble seeing hope for Fry’s Electronics’s future.
Where do they go from here?
We know the Palo Alto store is closing (due to a lease not being renewed), and there are reports of low stock and low staff around the country leaving many fans and shoppers dubious.
Aside from that, spokesmen for Fry’s say they are rebalancing, restocking for the holidays, adjusting inventory, and otherwise laying in for the long haul. It is true that, from Thanksgiving night through Epiphany, Fry’s does tend to pick up in pace, so it’s entirely possible that the next month will see a restructuring and new life.
At this point, we’ll have to wait and see if Santa brings a new life to Fry’s Electronics this Christmas season.
Where can we go from here?
On the upside, two other mainstays are holding up fairly well.
After an early morning fire in April 2019 destroyed their Sunnyvale location on El Camino, Central Computer (another 1985 Silicon Valley classic) is opening a new Sunnyvale store over near where HRO (and Disk Drive Depot and Action Surplus and the original Fry’s store) used to be. Signage and social media say it should be open by the end of the year. In the meantime, they have locations in Santa Clara, San Mateo, Fremont, and San Francisco.
And after formally going out of business in January 2019 after 54 years, Halted/HSC was bought by Excess Solutions, and they’re settling in nicely at the 7th St and Alma location in San Jose. You’ll find classic Halted stock and some of the classic Halted staff alongside the surplus gear, furniture, office supplies, and components that Excess Solutions has been known for.
If you’re looking for a smaller component source, Anchor Electronics is still around in an industrial part of Santa Clara.
And assuming Fry’s doesn’t close down their Sunnyvale store before then, you can look forward to the return of the Electronics Flea Market on March 14, 2020, in the side parking lot at Fry’s Sunnyvale.
All may not be lost, but it seems like it sometimes.



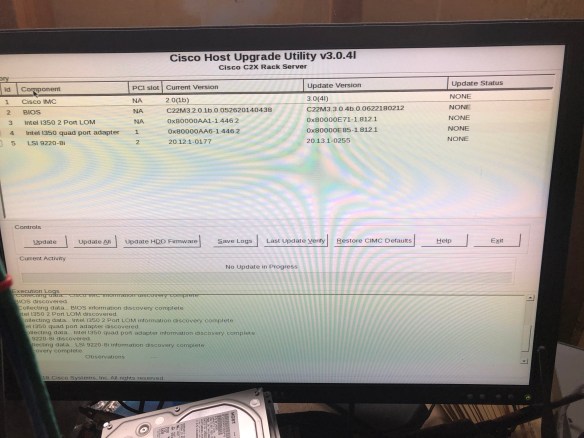



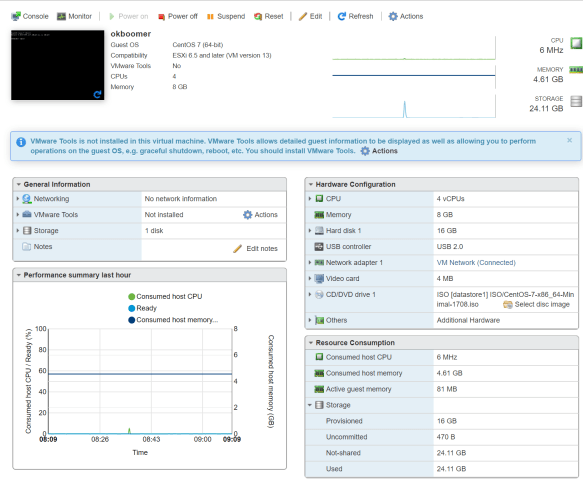 So where do we go from here?
So where do we go from here? Next up, adding some more storage (maybe SSD if I can find something that will work), maybe bumping the RAM up a bit, and doing something useful with the box. It only draws 80-100 watts under light use, so I’m okay with it being a 24/7 machine, and it’s quiet and in the garage so it shouldn’t scare the neighbors.
Next up, adding some more storage (maybe SSD if I can find something that will work), maybe bumping the RAM up a bit, and doing something useful with the box. It only draws 80-100 watts under light use, so I’m okay with it being a 24/7 machine, and it’s quiet and in the garage so it shouldn’t scare the neighbors.







