Update: At the time I wrote this post (February 2014), I was not a Cisco employee. Between June 2014-November 2020 I worked for Cisco. between November 2020 and April 2023, I no longer worked for Cisco. And since April 2023, I again work for Cisco. This shouldn’t change anything about the post, and it is still just me and not an official publication, but since the original disclaimer below is not currently accurate, I thought I would clarify that.
I’ve been working on a series of posts about upgrading an integrated UCS environment, and realized about halfway through that a summary/overview would make sense as a starting point.
I recommend a refreshing beverage, as this is longer than I’d expected it to be.
I will note up front that this does not represent the official presentation of UCS by Cisco, and will have errors and omissions. It does reflect my understanding and positioning of the platform, based on two years and change of immersive experience. It is also focused on C-Series (rack-mount servers), not B-Series (blade servers and chassis), as I have been 100% in the C-series side of the platform, although I try to share a reasonable level of detail that’s applicable to both. And I expect it will provide a good starting point to understanding the Unified Computing System from Cisco.
Unified Computing System – Wait, What?
UCS, or Unified Computing System, is Cisco’s foray into the server market, with integrated network, storage, management, and of course server platforms. As a server admin primarily, I think of it as a utility computing platform, similar to the utility storage concept that 3PAR introduced in the early 2000s. You have a management infrastructure that simplifies structured deployment, monitoring, and operation of your servers, reducing the number of inflection points (when deployed properly) to coordinate firmware, provisioning, hardware maintenance, and server identity.

UCS includes two types of servers. The original rollout in 2009 included a blade server platform, generally known as B-Series or Chassis servers. I would guess that 9 out of 10 people you talk to about UCS think B-Series blades when you say UCS. Converged networking happens inside the blade chassis on an I/O Module, or IOM, also known as a Fabric Extender, or FEX. Local storage lives on the blades if needed, with up to 4 2.5″ drives available on full-width blades (2 drives on half-width), and a mezzanine card slot for a converged network adapter and/or a solid state device.
At some point along the way, it seems customers wanted more storage than a blade provides, and more I/O expansion capacity, so Cisco rolled out a rack-mount product line, the C-Series “pizza box” servers, which provided familiar PCI-e slots, no less than twice the drive bays (8 2.5″ or 4 3.5″ on the lowest storage density C200/C220 models), and an access convergence layer outside the server in the form of a Fabric Extender, or FEX, a Nexus 2200-series switch.
Both platforms are designed to go upstream to a Fabric Interconnect, or FI, in the form of a UCS 6100 or 6200 series device. The FI is the UCS environment’s egress point; all servers (blade and/or rack-mount) in a single UCS domain or “pod” will connect to each other and the outside world through the FI. Storage networking to FCoE and iSCSI storage devices happens at this level, as does conventional Ethernet uplink.
So far it sounds pretty normal. Isn’t it?
You can use Cisco UCS C-series rack-mount servers independently without a FI, in the same way you might use a Dell PowerEdge R-series or HP ProLiant DL-series server. They work in standalone mode with a robust integrated management controller (CIMC) that is analogous to iDRAC or iLO, and they present as industry standard servers. The fully-featured CIMC functionality is included in the server (no add-on licensing, even for virtual media), and there’s even a potent XML API for the standalone API.
Many of the largest deployments of Cisco UCS C-Series servers work this way, and in the early days of my deployment, it was actually the only option (so we had standalone servers running bare metal OSes managed on a per-server basis). And for storage-dense environments, this method does have its charm.
The real power of the UCS environment, however, comes out when you put the servers under UCS Manager, or UCSM. This is what’s called an “integrated” environment, as opposed to a “standalone” environment where you manage through the individual CIMC on each server.
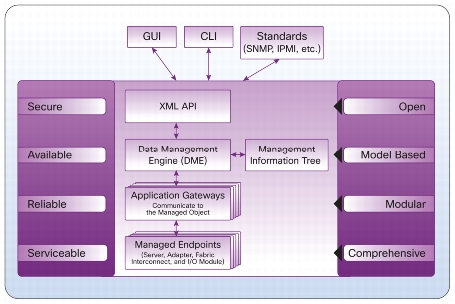
UCSM lives inside the Fabric Interconnect, and is at its core a database of system elements and states called the Data Management Engine or DME. The DME uses Application Gateways to talk to the managed physical aspects of the system–server baseboard (think IPMI), supported controllers (CNAs and disk controllers), I/O subsystem (IOM/FEX), and the FI itself.
UCSM is both this management infrastructure, and the common Java GUI used to interact with its XML API. While many people do use the UCSM Java layer to monitor and manage the platform, you can use a CLI (via ssh to the FI), or write your own API clients. There are also standard offerings to use PowerShell on Windows or a Python shell on UNIX to manage via the API.
What’s this profile stuff all about?
A key part of UCS’s benefit are the concepts of policies, profiles, and templates.
Policy is a standard definition of an aspect of a server. For example, there are BIOS policies (defining how the BIOS is set up, including C-state handling and power management), firmware policies (setting a package of firmware levels for system BIOS, CIMC, and supported I/O controllers), disk configuration policies (providing initial RAID configuration for storage).
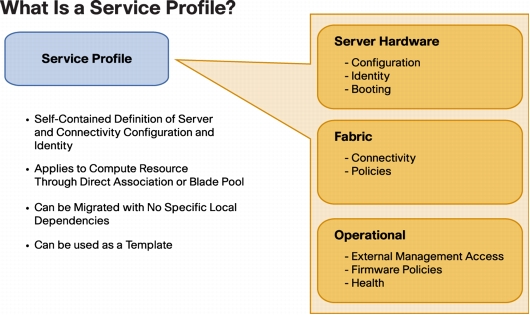
A Service Profile (SP) contains all the policies and data points that define a “server” in the role sense. If you remember Sun servers with the configuration smart card, that card (when implemented) would contain the profile for that server. In UCS-land, this would include BIOS, firmware, disk configuration, network identity (MAC addresses, VLANs, WWNs, etc) and other specific information that gives a server instance its identity. If you don’t have local storage, and you had to swap out a server for another piece of bare metal and have it come up as the previous server, the profile has all the information that makes that happen.
A Service Profile Template provides a pattern for creating service profiles as needed, providing consistency across server provisioning and redeployment.
There are also templates for things like network interfaces (vNIC, vHBA, and iSCSI templates) which become elements of a Service Profile or a SP Template. You might have a basic profile that covers, say, your web server design. You could have separate SP templates for Production (prod VLANs, SAN configuration) and Test (QA VLANs, local disk boot), sharing the same base hardware policies.
And there are server pools, which define a class of servers based on various characteristics (i.e. all 96GB dual socket servers, or all 1U servers with 8 local disks, or all servers you manually add to the pool). You can then associate that pool with a SP template, so that when a matching server is discovered in your UCS environment, it gets assigned to an appropriate template and can be automatically provisioned on power-up.
There are a lot more features you can take advantage of, from logging and alerting to call-home support features, to almost-one-click firmware upgrades across a domain, but that’s beyond the scope of this post.
I hear you can only have 160 servers though.
This is true, in a sense, much like you can only have 4 people in a car (but you can have multiple cars). A single UCS Manager can handle 160 servers between B-Series and C-Series. This is probably a dense five datacenter racks’ worth of servers, or 20 blade chassis, or some mix thereof (i.e. 10 chassis of 8 B-Series blades each, plus 80 rack-mount C-Series servers). But that’s not as bad a limitation as some vendors make it out to be.
You can address the XML API on multiple UCS Manager instances. A management tool might check inventory on all of your UCSM domains to find the element (server, policy, profile) that you want to manage, and then act on it by talking to that specific UCSM domain. Devops powers activate? This will get confusing if you create policies/profiles/templates at different times (i.e. while you’re waiting for your tools team to write a management tool).
But there’s something easier.
UCS Central is a Cisco-provided layer above the UCSM instances, that provides you with central management of all aspects of the UCS Manager across multiple domains. It’s a “write once, apply everywhere” model of policies and templates, that allows central monitoring and management of your environment across domains and datacenters.
UCS Central is an add-on product that may incur additional charges, especially if you have more than five UCS domains to manage. Support is not included with the base product. But when you get anywhere close to that scale, it may well be worth it. Oh, and in case you didn’t see this coming, there’s an XML API to UCS Central as well.
I don’t have a six figure budget to try this out. What can I do?
I’m glad you asked. Cisco makes a free “Platform Emulator” available. It’s a VM commonly referred to as UCSPE, downloadable for free from Cisco and run under the virtualization platform of your choice (including VMware Player, Fusion, Workstation, or others).
The UCSPE should let you get a feel for how UCSM and server management works, and as of the 2.2 release lets you try out firmware updates as well (with some slightly dehydrated versions of the firmware packages).
It obviously won’t let you run OSes on the emulated servers, and it’s not a replacement for an actual UCS server environment, but it will get you started.
If you have access to a real UCS environment, you can back up that physical environment’s config and load it into the UCSPE system. This will let you experiment with real world configurations (including scripting/tools development) without taking your production environment down.
Is Cisco UCS the right solution to everything?

Grumpy cat says “No.” And I just heard my Cisco friends’ hearts drop. But hear me out, folks.
To be completely honest, the sweet spot for UCS is a utility computing design. If you have standard server designs that are fairly homogeneous, this is a very good fit. If your environment is based around some combination of Ethernet, iSCSI, and FCoE, you’re covered. If your snowflake servers are running under a standard virtualization platform, you’re probably covered as well.
On the other hand, if you build a 12GB server here, a 27.5GB server there, a 66GB server with
FCoTR and a USB ballerina over there, it’s not a good fit. If you really need to run 32-bit operating systems on bare metal, you’re also going to run up against some challenges. Official driver support is limited to 21st Century 64-bit operating systems.
If you have a requirement for enormous local storage (more than, say, 24-48TB of disk), there are some better choices as well; the largest currently available UCS server holds either 12 3.5″ or 24 2.5″ drives. If you need a wide range of varied network and storage adapters beyond what’s supported under UCS (direct attach fibre channel, OC3/OC12 cards, modems, etc.), you might consider another platform that’s more generic.
Service profiles let you replace a server without reconfiguring your environment, but if every server is different, you’re not going to be able to use service profiles effectively. You can, of course, run UCS C-Series systems in standalone mode, with bare metal OSes or hypervisors, and they’ll work fine (with the 32-bit OS caveat above), and many companies do this in substantial volume, but you will lose some (not all) of the differentiation between Cisco UCS and other platforms.
Disclaimers:
I’ve worked with Cisco UCS as part of my day job for about two years. I don’t work for Cisco, and I’m not posting this as a representative of my employer or of Cisco. Any errors, omissions, confusion, or mislaid plans of mice and men gone astray are mine alone.
More details:

 UCS includes two types of servers. The original rollout in 2009 included a blade server platform, generally known as B-Series or Chassis servers. I would guess that 9 out of 10 people you talk to about UCS think B-Series blades when you say UCS. Converged networking happens inside the blade chassis on an I/O Module, or IOM, also known as a Fabric Extender, or FEX. Local storage lives on the blades if needed, with up to 4 2.5″ drives available on full-width blades (2 drives on half-width), and a mezzanine card slot for a converged network adapter and/or a solid state device.
UCS includes two types of servers. The original rollout in 2009 included a blade server platform, generally known as B-Series or Chassis servers. I would guess that 9 out of 10 people you talk to about UCS think B-Series blades when you say UCS. Converged networking happens inside the blade chassis on an I/O Module, or IOM, also known as a Fabric Extender, or FEX. Local storage lives on the blades if needed, with up to 4 2.5″ drives available on full-width blades (2 drives on half-width), and a mezzanine card slot for a converged network adapter and/or a solid state device.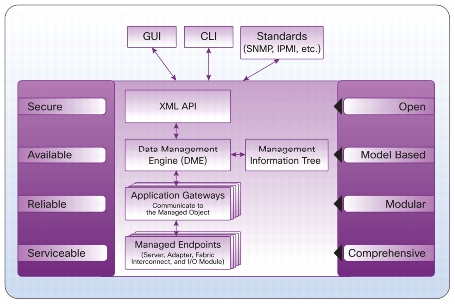 UCSM lives inside the Fabric Interconnect, and is at its core a database of system elements and states called the Data Management Engine or DME. The DME uses Application Gateways to talk to the managed physical aspects of the system–server baseboard (think IPMI), supported controllers (CNAs and disk controllers), I/O subsystem (IOM/FEX), and the FI itself.
UCSM lives inside the Fabric Interconnect, and is at its core a database of system elements and states called the Data Management Engine or DME. The DME uses Application Gateways to talk to the managed physical aspects of the system–server baseboard (think IPMI), supported controllers (CNAs and disk controllers), I/O subsystem (IOM/FEX), and the FI itself.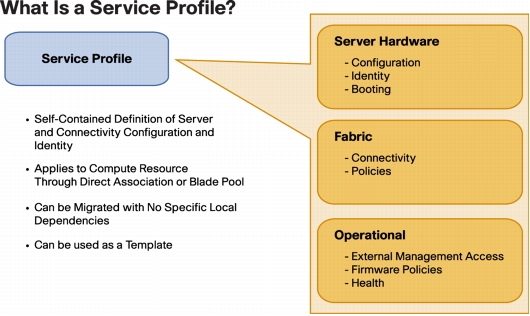 A Service Profile (SP) contains all the policies and data points that define a “server” in the role sense. If you remember Sun servers with the configuration smart card, that card (when implemented) would contain the profile for that server. In UCS-land, this would include BIOS, firmware, disk configuration, network identity (MAC addresses, VLANs, WWNs, etc) and other specific information that gives a server instance its identity. If you don’t have local storage, and you had to swap out a server for another piece of bare metal and have it come up as the previous server, the profile has all the information that makes that happen.
A Service Profile (SP) contains all the policies and data points that define a “server” in the role sense. If you remember Sun servers with the configuration smart card, that card (when implemented) would contain the profile for that server. In UCS-land, this would include BIOS, firmware, disk configuration, network identity (MAC addresses, VLANs, WWNs, etc) and other specific information that gives a server instance its identity. If you don’t have local storage, and you had to swap out a server for another piece of bare metal and have it come up as the previous server, the profile has all the information that makes that happen. The UCSPE should let you get a feel for how UCSM and server management works, and as of the 2.2 release lets you try out firmware updates as well (with some slightly dehydrated versions of the firmware packages).
The UCSPE should let you get a feel for how UCSM and server management works, and as of the 2.2 release lets you try out firmware updates as well (with some slightly dehydrated versions of the firmware packages).
Really nice write up Robert. I think the mention of the Platform Emulator is a really nice point. I still see lots of DC Cert candidates unaware this is available, even though one of the CLN members posted a nice summary of this… (I don’t want to spam the comments here, but I might Tweet you a link)
How would you feel about doing a little “Member Led Study Session” on the emulator? Also, (last thing I promise) I’d be interested to see if you’ve tried the CoudLabs environment out…
LikeLike
Hi Matt. I haven’t tried CloudLabs although I’ve seen some CLN posts about access. Maybe when I get back from Gallifrey One I’ll check into it. And I can probably work on something with the emulator. Hoping to do a companion video to my upgrade series, to illustrate what gets done for a firmware/infra upgrade.
And by all means, feel free to post links to things of interest to other readers. 🙂
LikeLike
Great, and now I’m jealous of your trip to Gallifrey One! (throwing the 12yr old a Dr. Who bday party this weekend, maybe next year I take him to that for his bday…)
Here’s the link to the CLN thread about the emulator: https://learningnetwork.cisco.com/docs/DOC-21752 – It’s a bit tough to follow, but a very nice overview none the less.
Save travels my friend!
LikeLike
Pingback: Cisco UCS: CCNA: DC?
Pingback: Looking ahead into 2019 with rsts11 | rsts11 – Robert Novak on system administration
Pingback: Chia update and frequently answered questions | rsts11 – Robert Novak on system administration
Pingback: A little bit about Hot UCS Summer, and a realworlducs guest blog post | rsts11 – Robert Novak on system administration